- The Protein-DNA Benchmark
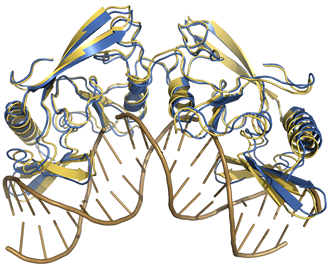 Biomolecular docking aims at predicting the structure
of a complex given the three dimensional structures of its components. Although much improvement has been made in the field of protein-protein docking, in the case of protein-DNA complexes,
however, progress lags behind. The scarcity of information for proper identification of interaction surfaces on DNA and its inherent flexibility have
hampered the development of effective docking methods. To facilitate the development of effective protein-DNA docking methods a set of well-defined test cases that form a common
ground for development, validation and comparison of docking methods is necessary.
Biomolecular docking aims at predicting the structure
of a complex given the three dimensional structures of its components. Although much improvement has been made in the field of protein-protein docking, in the case of protein-DNA complexes,
however, progress lags behind. The scarcity of information for proper identification of interaction surfaces on DNA and its inherent flexibility have
hampered the development of effective docking methods. To facilitate the development of effective protein-DNA docking methods a set of well-defined test cases that form a common
ground for development, validation and comparison of docking methods is necessary.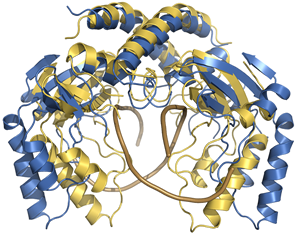 We present here a protein-DNA docking benchmark containing
47 unbound-unbound test cases, of which 13 are classified as easy cases, 22 as intermediate cases and 12 as difficult cases. The latter show considerable structural
rearrangement upon complex formation. DNA-specific modifications such as flipped out bases and base modifications are included. The benchmark covers all major
types of DNA binding proteins according to the classifications of Luscombe et al. The variety in test cases make this non-redundant
benchmark a useful tool for comparison and further development of protein-DNA docking methods.
We present here a protein-DNA docking benchmark containing
47 unbound-unbound test cases, of which 13 are classified as easy cases, 22 as intermediate cases and 12 as difficult cases. The latter show considerable structural
rearrangement upon complex formation. DNA-specific modifications such as flipped out bases and base modifications are included. The benchmark covers all major
types of DNA binding proteins according to the classifications of Luscombe et al. The variety in test cases make this non-redundant
benchmark a useful tool for comparison and further development of protein-DNA docking methods.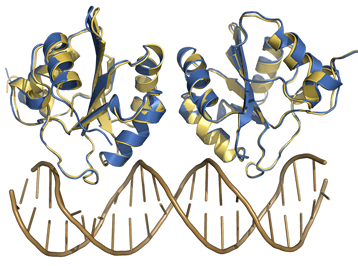 We developed the protein-DNA benchmark to be of general
use to the docking community. We welcome all suggestions aimed at improving or expanding the benchmark. You can email suggestions to Alexandre M.J.J. Bonvin.
We developed the protein-DNA benchmark to be of general
use to the docking community. We welcome all suggestions aimed at improving or expanding the benchmark. You can email suggestions to Alexandre M.J.J. Bonvin.
- Benchmark Download and Version History
- Updates for the protein-DNA benchmark they will be posted here.
-
- 01-01-2008 | The original protein-DNA benchmark version 1.0 release. You can download a gziped version of the benchmark here.
- 14-08-2008 | Benchmark version 1.1: Minor updates. The bound to unbound residue mapping file (profit.dat) has been redesigned
to make it more flexible in use. The PDB structure file that represents the complex reconstructed from the unbound processed
components after superimposition contained more than one instance of the same complex coordinate set. This has been fixed. You
can download a gziped version of benchmark version 1.1 here
- 22-09-2009 | Benchmark version 1.2: Small fixes in residue mapping for two entries. For two entries (1EYU,1RVA) the unbound
protein was composed off two distinct subunits. These have now been separated into individual pdb files and all other files
have been adjusted accordingly. You can download a gziped version of benchmark version 1.2
here
- Citing the benchmark
- When using the protein-DNA docking benchmark please cite using the following reference:
-
- van Dijk, M. and A.M.J.J. Bonvin (2008) A protein-DNA docking benchmark. Nucleic Acids Res, 1-5, published
online (doi:10.1093/nar/gkn386). | Read more >>
- References
-
- Luscombe, N.M., Austin, S.E., Berman, H.M. and J.M. Thornton (2000) An overview of the structures of protein-DNA complexes. Genome Biol, 1,1
published online.
- van Dijk, M., van Dijk, A. D., Hsu, V., Boelens, R., Bonvin, A. M. (2006) Information-driven protein-DNA docking using HADDOCK: it is a matter of
flexibility. Nucleic Acids Res, 34(11). 3317-25. HADDOCK website